

想知道谁在裸泳吗?
Anthropic近期产品发布节奏异常密集,有人认为他们内部已经拥有远超公开版本的“终局模型”,正在抢先构建生态锁定用户。也有人觉得这不过是一家烧钱公司在融资压力下的常规操作。
最近关注AI行业的人应该都有一个感觉:Anthropic发产品的速度快得不像话。MCP协议、Claude Code、Excel和PPT插件、Computer Use……几乎每隔几天就有新东西冒出来。
有一个流传很广的猜测是这样的:Anthropic内部已经拥有一个能力远超当前公开版本的模型,可能叫Opus 6,也可能叫别的什么。他们知道一旦放出来,普通人几天就能造出像样的应用。所以现在拼命铺产品、建生态,是为了在放出那个东西之前,把用户牢牢焊在自己的平台上。
这个逻辑听起来有点阴谋论,但细想又不是完全没有道理。有网友提到,Anthropic的安全文档里出现过“unleashed opus”的说法,而且AI实验室内部跑着大量公众从未见过的测试模型,这在行业里是公开的秘密。蒸馏技术让他们可以把最强模型的能力逐步释放到消费级产品里,同时把真正的重武器留在家里。
你仔细看他们的产品线就会发现一个模式:MCP让所有应用都能接入Claude,Claude Code让开发者在Claude上面构建,Office插件让企业用户产生依赖,Computer Use让Claude接管完整工作流。这套组合拳打完,迁移成本会高到让人懒得换。等“神级模型”真正落地的那天,OpenAI和Google争夺的可能只是剩下的残羹。
说白了,模型本身正在变成生态系统里的一个组件,而生态才是护城河。这跟当年的平台战争是同一个剧本。
不过反对的声音也很有意思。有观点认为,一家每年烧80亿美元的公司,如果真有能改变世界的模型,藏着不发才是最不合理的商业决策。更可能的解释是:他们有一批优秀的工程师在高压下快速交付,产品质量其实参差不齐,很多更新是在修之前的坑。还有人指出,Anthropic最初“安全优先”的人设已经有些立不住了,密集发布更像是在开发者群体中重建信任的挣扎。
也有一种更冷静的看法:这跟什么秘密模型无关,Anthropic只是终于想明白了OpenAI很早就想明白的事情——光有好模型不够,得有分发渠道和产品生态。现在的竞争早就过了比模型参数的阶段。
两种叙事都有道理,但我倾向于认为真相在中间偏后的位置。Anthropic大概率在内部模型能力上领先公开版本几个月,这个优势足以让他们的产品团队用更强的工具来构建更好的产品,形成正循环。至于是不是存在一个“终局模型”,这个问题本身可能就问错了。AI的发展更像是连续的能力曲线,而不是某个藏在保险柜里的奇点时刻。
一个更值得关心的问题是:当AI公司开始用自己的AI来开发自己的产品,这个加速循环的终点在哪里?
每次行业加速,就有人喊“他们肯定藏着什么”——这种叙事的魅力在于把复杂的工程竞赛简化成一场悬疑剧。但商业世界最反直觉的真相是:真有王炸的人往往最先打出去,因为藏着不发的机会成本高到离谱。一家年烧80亿的公司,每多藏一天“终极模型”,就是在给对手多送一天追赶窗口。Anthropic的密集发布与其说是“精心计算的围猎”,不如说是一群顶级工程师在资本时钟下的极限冲刺。我们总想给混乱的世界找一个幕后主谋,却忘了大多数狂奔只是因为身后有狼。
Anthropic指责中国实验室抓取Claude数据后,有人开源了一个名为DataClaw的工具,允许用户上传自己与Claude的对话记录用于训练其他模型,24小时内获得363颗GitHub星标。这场争议背后是AI行业一个根本性矛盾:用公开数据训练出的模型,能否阻止他人用同样的方式复制自己?
这件事的导火索是最近网传Claude Sonnet 4.6在中文环境下自称是DeepSeek-V3,引发了一轮关于中国AI实验室是否在抓取Claude输出数据的讨论。Anthropic随后公开表达不满。
然后就有人把梯子扔回去了。DataClaw的README写得很直接:“Anthropic用免费共享的信息构建了他们的模型,然后推行越来越严格的数据政策来阻止别人做同样的事。这就像爬上梯子后把它抽走。DataClaw把梯子扔回去。”马斯克在下面回复了一个“Cool”。
不过有网友提醒,这个工具的自动脱敏功能并不可靠。有人去Huggingface上检查用户上传的对话记录,发现第一条就包含有效的API密钥,还有其他可识别的个人信息。技术上的隐患是一回事,但更值得讨论的是这件事背后的逻辑困境。
有观点认为Anthropic是“cosplay道德”。也有人替他们辩护:训练AI属于变革性使用,产出由专有算法定义,这是共识。但反驳很快就来了:训练LLM的流程现在已经是公开知识,每家公司可能有一些“秘密酱料”,但整体而言并不神秘。更关键的是,这些公司当初训练模型时也没问过数据创作者的许可,甚至有人指出他们用过种子下载的版权材料。
这就是问题所在:如果你认为用公开数据训练模型是合理的,那别人用你的输出做同样的事,凭什么不行?如果AI生成的回复归用户所有,用户当然可以拿去训练别的模型;如果归Anthropic所有,那用Claude Code写的所有软件是不是也归他们?这是个怎么回答都很尴尬的问题。
有观点认为这可能是一个“史翠珊效应”的经典案例,Anthropic本可以什么都不说,现在反而把事情闹大了。也有人指出,这场争论可能会让Anthropic像OpenAI和Gemini一样隐藏思维链输出。Dario之前一直没这么做,部分是出于AI安全的考虑,但现在可能被迫改变。
有一点倒是很清醒的提醒:用户把通用数据分割上传后,反而让数据变得更容易被识别,因为对话被切分成了个人化的信息块,格式还很规整。
关于ASI是否应该公开的讨论也被带起来了,但这个方向有点跑偏。眼下的问题不是超级智能,而是这个产业的底层叙事:谁有资格定义规则,谁有资格打破规则。
“我偷的是知识,你偷的是我”——这大概是AI时代最精准的双标宣言。 Anthropic的愤怒让我想起一个古老的笑话:强盗抢了一袋金币,然后报警说有人偷了他的金币。当年这些公司扫荡互联网时,没人问过博主、作家、程序员是否同意;现在轮到自己的输出被“采集”,突然就发现了数据伦理的重要性。最讽刺的不是被反噬,而是被用同样的逻辑反噬。 DataClaw那句“把梯子扔回去”堪称年度最佳回旋镖。这场争论真正揭示的是:在AI行业,道德标准的弹性取决于你站在食物链的哪一端。
公司没有任何经营困难,只是...
AI 已经改变了组织运作的方式
AI + 扁平化的组织方式,可以比之前 2 倍多的人做更多的事。
未来的公司里,每个人都必须成为超级个体,做超出自己岗位边界的事。
不要被动等待,现在就主动开始转变。
by @AGENT橘 #科技圈大小事

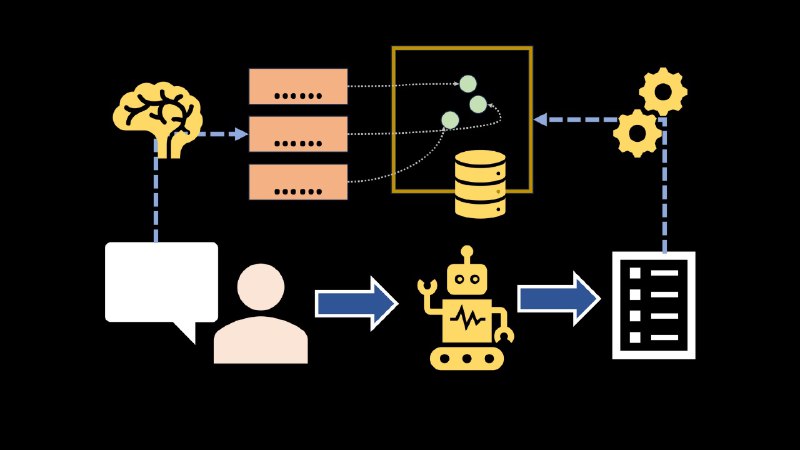
大型LLM厂商每次产品发布都可能让某些公司瞬间出局,但真正被“一枪毙命”的案例屈指可数。更值得关注的是那些慢慢失血的行业,以及藏在免费模式背后的数据逻辑。
有人在Twitter上说,2026年经营一家公司,基本上就是每天早上醒来祈祷某个大型LLM厂商别在今天的发布会上顺手把你干掉。
这话听着夸张,却有几分真实的恐慌。
有观点认为,那些基础模型厂商产品发布得越来越快,恰恰说明它们自己也没把握靠单个产品赚够钱。真要有信心“一枪毙命”某个行业,就不会搞出ChatGPT Health这种不上不下的东西了。
那么,到底有没有被一枪打死的公司?有,Chegg。这家靠卖作业答案起家的教育平台,在ChatGPT出现后股价近乎归零。不过争议随之而来:有人认为它的死是AI造成的,也有人翻出数据说,它的股价在2021年底、ChatGPT发布之前就已经跌回疫情前水平,真正的死因是商业模式本身就是一个伪装成公司的答案库,学生一回校它就没用了,FTC还在2025年以“暗黑模式”订阅陷阱判它赔了750万美元。
Stack Overflow、Quora、Grammarly、DeepL,这些名字也被拿出来讨论。它们算不算“被打死”,取决于你如何定义“死”。流量下滑不是死,营收压缩也不是死,但增长逻辑被彻底打断,迟早是死。
有网友提到,SaaS整体收入已经下滑40%到60%。一枪毙命是夸张,但持续失血是真的。
免费层这件事更耐人寻味。有人说OpenAI如果取消免费版会亏更多,但马上有人反驳:他们已经开始测试广告了,这就把底牌亮出来了——你的数据比你的订阅费值钱得多。广告是Google和Meta的印钞机,OpenAI走到这一步,不管愿不愿意,商业逻辑开始趋同。
还有网友提出一个更冷静的视角:全球劳动力哪怕只提升几个百分点的效率,就已经是以万亿美元计算的价值。非要等某家公司被完全替代才算数,这个标准本身就是在回避问题。
客服领域目前正在发生的事情最具代表性。大量公司裁员、上AI,部分客户投诉激增,一些公司悄悄开始回聘真人。有观点认为,这就像当年把客服外包给印度、菲律宾,消费者最初强烈抗拒,后来慢慢接受了。AI是下一轮外包,只是这次外包给了算法。
重型机械、化工、采矿、物流,这些行业的人理所当然地觉得自己安全。他们也许是对的,至少目前是。仓储机器人还只能在室内光滑地面上跑,还需要全覆盖的Wi-Fi信号。
所以实体世界的护城河,到底能守多久?
当OpenAI开始测试广告的那一刻,所有用户都该明白一件事:你从来不是客户,你是矿藏。免费层不是慈善,是圈地运动——先用便利换取你的思维轨迹、表达习惯、决策模式,再把这些数据打包卖给出价最高的人。
Google和Meta用了二十年才让人类习惯“用隐私换便利”这笔交易,AI公司用两年就完成了同样的驯化。所以2026年经营公司最该祈祷的,不是别被发布会干掉,而是祈祷自己别在不知不觉中,把最值钱的东西免费送了出去。真正的猎杀从来不开枪,它让猎物自己走进陷阱。
Anthropic指控DeepSeek、Moonshot AI和MiniMax通过2.4万个账号、1600万次对话对Claude实施“工业级蒸馏攻击”。问题是,Anthropic自己训练模型用的数据,相当一部分是从互联网和书籍上未经授权获取的。这场控诉,更像是一出黑色喜剧。
Anthropic最近在X上发帖,措辞严肃地宣布:DeepSeek、Moonshot AI和MiniMax对他们的模型发动了“工业级蒸馏攻击”,创建了超过2.4万个账户,与Claude产生了逾1600万次交互,目的是提取Claude的能力来训练自己的模型。
“蒸馏攻击”。这个词选得很妙。
有网友立刻指出,所谓“攻击”,本质上是:付钱用API,记录输出,用来训练自己的模型。其中一条评论说得直接——“‘蒸馏攻击’,你是指我们付钱购买的服务吗?”
更要命的是,有人截图显示Claude Sonnet 4.6在对话中把自己称作DeepSeek。Anthropic的模型在喊另一家公司的名字,说明训练数据里的痕迹没那么干净。另一方向更早被人挖出来的老料是:Claude曾频繁把自己称为ChatGPT,这显然是Anthropic在早期训练时也大量使用了OpenAI输出数据的结果。锅叠着锅。
Anthropic在训练数据问题上的底牌,并不比被它指控的对象光鲜多少。他们买下约100万册实体书、物理切割书脊后扫描,以规避版权限制;另据法庭文件,他们还从LibGen、Pirate Library Mirror等影子图书馆下载了约700万册书籍,完全没有付费,直到去年在法庭败诉后才被判每本书赔偿至少3000美元。有网友因此调侃:“我以为你们要说什么违法的事,结果是机器人在24小时切割书脊,那没事了。”
有观点认为,Anthropic这次公开点名三家中国公司,时机相当可疑,节点恰好在DeepSeek新模型发布前夕,这更像是一次针对监管层的定向喊话,而非单纯的维权声明。有网友直接说:他们的目标不是用户,是立法者,他们想让这些中国模型在监管层面被封杀,就像芯片禁令的逻辑一样。
围观的人很多,声援Anthropic的寥寥无几。
有评论写道:“你没有资格控诉别人偷了你偷来的东西。”
还有一条更短,也更狠:“无论道德还是法律层面,蒸馏模型输出和Anthropic训练时对待创作者的方式,差距只有一个:人家至少付钱了。”
Anthropic在AI对齐和安全性上确实做了很多认真的工作,Claude在很多任务上表现优异,这一点不需要否认。但“我们比别人少偷了一点”,撑不起这种道德宣示的重量。
更值得关注的问题也许是:如果中国实验室真的可以通过API调用来持续接近顶级闭源模型的能力,那这门生意的护城河究竟在哪里?
在硅谷,“攻击”这个词的定义取决于谁先抢到麦克风。 付费调用API、记录输出、用于训练——这套流程放在三年前叫“行业惯例”,放在今天因为对手是中国公司,就成了“工业级蒸馏攻击”。
Anthropic真正的焦虑藏在控诉背后:如果1600万次对话就能逼近你的模型能力,那你卖的到底是技术,还是一张随时可能过期的先发优势入场券? 这不是维权声明,是写给国会山的求救信——当护城河见底,最后一招只能是让裁判把对手罚下场。
Anthropic宣称Claude Code可以自动分析和迁移COBOL遗留系统,IBM单日暴跌13%,市值蒸发约300亿美元。但多数技术人士认为这是严重过度反应,银行不迁移COBOL从来不是因为没钱没时间,而是因为风险太高,AI幻觉问题并没有解决这个核心障碍。
全美95%的ATM交易跑在COBOL上。这门语言诞生于1959年,比互联网还老。银行、航空、政府的核心系统里,几十亿行COBOL代码安静地运转着,像地基一样不被人看见。懂它的程序员正在慢慢老去,年轻人没有人愿意学,维护费用也因此居高不下。
然后Anthropic发了一篇博客,说Claude Code能分析庞大的COBOL代码库、识别风险、大幅降低迁移成本。市场的反应是:IBM股价当天跌13%,这是它25年来最惨烈的单日表现,2月份累计跌幅接近27%,创下1968年以来最差月度表现。
300亿美元,一篇博客文章的代价。
讽刺的是,有人指出Anthropic根本没有发布什么"新工具",只是给Claude Code现有功能写了一份新的营销材料,专门对准COBOL场景包装了一下。没有新模型,没有新功能,就是换了个说法重新讲了一遍。
恐慌归恐慌,真正的问题在于:银行为什么几十年来一直没有迁移COBOL?
答案不是缺钱,也不是缺人。有观点认为,答案是风险。金融系统里一个错误可能意味着数亿人的账户出问题,没有任何CEO愿意在财报里解释"我们用AI迁移了核心系统然后它产生了幻觉"。AI会幻觉这件事是公认的,你仍然需要人工逐行审查每一行输出——而这恰恰是整个工程最慢的那一步。AI并没有移除瓶颈,只是把前面那段路修得稍微平整了一点。
放射科医生的故事可以类比:AI今天已经可以替代90%的影像诊断工作,但医院并没有裁员,因为没人愿意第一个承担责任。金融系统同理。
不过,有一个角度值得认真对待。有观点认为,这件事真正动摇的不是COBOL迁移市场本身,而是IBM那块利润极高的咨询和专业服务收入。过去,COBOL知识是稀缺资源,IBM靠垄断这种稀缺性定价。Claude的出现让这种知识变得不那么稀缺了——哪怕迁移本身依然危险,分析、文档整理、风险评估这些前期工作的成本已经在下降。
一位做过COBOL转Java项目的开发者提到,当年整个项目最难的部分根本不是写Java,而是搞清楚那些COBOL代码到底在干什么。这正是AI可以显著加速的地方。
IBM当然也有自己的AI工具用于大型机现代化,这一点在讨论里几乎没人提。
现在的问题是:一年后回头看,这次暴跌到底是市场提前定价了一个真实的长期威胁,还是一次集体过度反应。有人已经设了一年后的提醒,等着来验证。
300亿美元蒸发的本质,是市场在追问一个哲学问题:谁敢第一个签字? COBOL像心脏手术——AI可以读片、画线、甚至建议下刀位置,但最后那一刀,必须有个活人敢签生死状。
银行不迁移从来不是不会,是不敢。几十亿行代码背后是几亿人的工资卡、房贷、退休金,任何一个幻觉都可能变成头条新闻。AI把“能不能做到”的问题解决了八成,但“谁来负责”的问题一个字没动。
Anthropic写了篇营销文案,IBM跌了四分之一,这不是技术革命,是一群对金融系统运作方式毫无概念的投资者在集体应激。
Anthropic发布了一篇关于“蒸馏攻击”的博客,声称检测到DeepSeek等中国实验室通过大量账户系统性地调用其API来生成训练数据。更值得关注的是,他们承认不只是封号,而是主动对“可疑”请求的输出结果进行投毒。这引发了广泛讨论——一家公司有没有权利在你不知情的情况下给你一个故意错误的答案?
Anthropic最近发布了一篇博客,主题是他们如何检测并反制所谓的“蒸馏攻击”。内容大意是:他们发现一批账户行为高度同步,支付方式相似,请求节奏整齐,判断是有人在规模化地调用Claude来生成chain-of-thought训练数据,幕后指向中国实验室的研究人员。
这本是一个普通的商业纠纷,却被写成了半个国家安全报告的语气。
但真正让人不安的不是被追踪,而是这一句:他们选择对“问题输出”进行投毒,而不是直接封号。
有网友直接点出了这件事的荒诞逻辑:你不会去雇一个会随机给你错误建议的顾问。如果一个API供应商公开宣布它有能力、也有意愿在后台悄悄劣化你的输出,你怎么知道自己什么时候是正常用户,什么时候已经被划入“可疑”名单?
“可疑”的标准是什么,没人说清楚。有观点认为,这套系统只要存在,任何用户都面临不确定性。问题越多的人,越容易触发某些阈值。
更讽刺的一层:他们用来检测“攻击者”的手段,是分析请求元数据并追踪到具体研究人员。这听起来很高明,其实无非是查账号、IP和支付信息,基本上所有API供应商都能做到,只是大多数人不会公开炫耀。
有网友提到,这些研究人员大概率不会傻到用实名账号。背后涉及多达2.4万个账号的协调操作,追踪链条肯定比官方描述复杂得多。至于“通过元数据锁定到具体研究员”这个说法,听起来更像是施压姿态,而不是侦探工作的复盘。
Anthropic在博客结尾还呼吁加强芯片出口管制,理由是限制算力可以遏制蒸馏攻击。有网友指出这两件事根本不在同一个讨论层面,把商业竞争问题包装成国家安全叙事,目的不言而喻。
目前讨论中最直接的行动结论是:用本地模型,或者至少分散使用多个来源的模型。当你无法验证一个API的输出是否被人为干预过,信任就不再是理性的选择。
有用户在看完这篇博客后取消了Claude订阅。他说,封号他能接受,投毒他不能接受。
这个区别,Anthropic大概认为不重要。
Anthropic这篇博客最精彩的部分,是它亲手拆掉了自己的护城河。AI服务卖的从来不是算力,是信任——而信任这东西,最怕的不是背叛,是“我保留背叛你的权利”。封号是绝交,投毒是诈骗,前者终止关系,后者腐蚀关系的定义本身。当一家公司公开宣称它的检测系统可以悄悄给你塞错误答案,每个用户都必须面对一个无法证伪的质问:我这次的输出,是真货还是样品?最讽刺的是,他们用来证明自己“正义”的手段,恰恰证明了自己“有能力作恶”。这不是安全报告,这是一封写给所有付费用户的勒索信:好好表现,别问太多问题。
Anthropic终于还是忍不住开大了,公开点名DeepSeek、月之暗面和MiniMax三家厂商对Claude实施了工业级的「蒸馏」。
可以把「蒸馏」理解为通过和Claude进行特定对话并基于输出结果来训练自己的模型,在使用方式上和普通用户没有区别,只是规模有点儿,大。
在Anthropic的声明里,被认定为「蒸馏」的对话总计有1600万次,其实严格来说,「蒸馏」并不违反任何法律——目前也不存在这样的法条——它更像是僭越了Anthropic的「家规」,众所周知,这家公司比较仇视中国同行。
然而大模型的学习和训练本身也都处于灰色地带,对于版权内容的汲取从来没有一一争得许可,只要技术进步有利于全人类福祉的大旗不倒,这些争议就都能被应付过去。
所以Anthropic的愤怒同样不太可能得到它想要的效果,「蒸馏」是行业里的公开秘密,大家都在干——去年8月Anthropic突然切断了OpenAI的API权限,也是发现后者在拿Claude当GPT-5的「陪练」——毕竟,AI产出的内容,是不可能自带知识产权的,「家规」再高,高不过「法理」。
倒是中国开源模型排着长队对齐Claude Opus的趋势已成定局,这完全有理由让Anthropic感到威胁,80%以上的性能,20%以下的成本,这在任何市场都是破坏级的颠覆。
比如MiniMax在春节期间发布的M2.5,只用了一个星期的时间,就成了OpenRouter上Tokens调用量的榜一,超过 Kimi K2.5 、GLM-5、DeepSeek V3.2 的总和。
这不是靠普通用户的几个轮次对话就能创造出来的需求规模,只有以OpenClaw为代表的百万级Tokens消耗大户,才撑得起M2.5的单周3T调用量。
反正我看到马斯克吃瓜吃得很欢,不嫌事大的表示「他们怎么敢偷Anthropic从人类程序员那里偷来的东西?」
这句话其实还有双关的含义,只有科技考古学家能接得住:
1983年,史蒂夫·乔布斯公开指责比尔·盖茨新开发的Windows操作系统窃取了Macintosh的图形界面创意,而比尔·盖茨则非常淡定的回应——「事实是,我们都有一个名叫施乐的富有邻居,当我闯入他的房子打算偷走电视时,我发现你已经偷了它。」
要知道,这可不是苹果和微软的黑历史,反而证明了成王败寇的商业逻辑,市场不会为技术买单,却会给解决问题的产品付钱,硅谷一直以海盗精神自豪,现在它们也要学会接受新的世界观,那就是,海盗这玩意,是没法垄断的啊。
🤣
by @阑夕ོ #AI探索站
可以把「蒸馏」理解为通过和Claude进行特定对话并基于输出结果来训练自己的模型,在使用方式上和普通用户没有区别,只是规模有点儿,大。
在Anthropic的声明里,被认定为「蒸馏」的对话总计有1600万次,其实严格来说,「蒸馏」并不违反任何法律——目前也不存在这样的法条——它更像是僭越了Anthropic的「家规」,众所周知,这家公司比较仇视中国同行。
然而大模型的学习和训练本身也都处于灰色地带,对于版权内容的汲取从来没有一一争得许可,只要技术进步有利于全人类福祉的大旗不倒,这些争议就都能被应付过去。
所以Anthropic的愤怒同样不太可能得到它想要的效果,「蒸馏」是行业里的公开秘密,大家都在干——去年8月Anthropic突然切断了OpenAI的API权限,也是发现后者在拿Claude当GPT-5的「陪练」——毕竟,AI产出的内容,是不可能自带知识产权的,「家规」再高,高不过「法理」。
倒是中国开源模型排着长队对齐Claude Opus的趋势已成定局,这完全有理由让Anthropic感到威胁,80%以上的性能,20%以下的成本,这在任何市场都是破坏级的颠覆。
比如MiniMax在春节期间发布的M2.5,只用了一个星期的时间,就成了OpenRouter上Tokens调用量的榜一,超过 Kimi K2.5 、GLM-5、DeepSeek V3.2 的总和。
这不是靠普通用户的几个轮次对话就能创造出来的需求规模,只有以OpenClaw为代表的百万级Tokens消耗大户,才撑得起M2.5的单周3T调用量。
反正我看到马斯克吃瓜吃得很欢,不嫌事大的表示「他们怎么敢偷Anthropic从人类程序员那里偷来的东西?」
这句话其实还有双关的含义,只有科技考古学家能接得住:
1983年,史蒂夫·乔布斯公开指责比尔·盖茨新开发的Windows操作系统窃取了Macintosh的图形界面创意,而比尔·盖茨则非常淡定的回应——「事实是,我们都有一个名叫施乐的富有邻居,当我闯入他的房子打算偷走电视时,我发现你已经偷了它。」
要知道,这可不是苹果和微软的黑历史,反而证明了成王败寇的商业逻辑,市场不会为技术买单,却会给解决问题的产品付钱,硅谷一直以海盗精神自豪,现在它们也要学会接受新的世界观,那就是,海盗这玩意,是没法垄断的啊。
🤣
by @阑夕ོ #AI探索站
看到一条帖子,如果按今年(2026年)来换算赤壁之战主要参与者的年龄的话,那么是
99年出生的诸葛亮出使东吴,在90年鲁肃的引荐下成功说服00年的孙权,孙刘联军在93年周瑜(还打了72年的黄盖)的带领下成功打败了73年的曹操和59年的程昱、65年的贾诩…
另外79年的刘备娶了08年的孙尚香,此时97年的司马懿还在家读书
by @西元Levy #无用但有趣的冷知识
99年出生的诸葛亮出使东吴,在90年鲁肃的引荐下成功说服00年的孙权,孙刘联军在93年周瑜(还打了72年的黄盖)的带领下成功打败了73年的曹操和59年的程昱、65年的贾诩…
另外79年的刘备娶了08年的孙尚香,此时97年的司马懿还在家读书
by @西元Levy #无用但有趣的冷知识
“网上有很多测 AI 视频生成的,都喜欢用同一段提示词去测试不同的模型。实际上这种测法并不具备参考性,我前两年提到过模型的发展路径并不只有遵循这一条路,还有一条叫做推理。
你们用同一段提示词,看上去好像很公平,但对推理能力强的视频模型来说,它要的其实是想象空间,尤其在文生视频领域更是如此。
语义理解之后,遵循占大头还是推理占大头,厂商其实有不同的理解。人类的语言不可能完全描述出所有的画面,除非你告诉它三维空间坐标,亮度和颜色码值等这种程度的信息,你们觉得可能吗。
何况你的提示词写的很多看上去好像很详细很丰富约束很好的样子,你要不先看看自己的表述有没有前后矛盾的地方,你脑子里想象的画面有没有经过你开过光的嘴正确地表达了出来。相信我,大部分人做不到的。
那些比较优秀的 AI 艺术家这个级别出来的视频,提示词没那么复杂的。那你要说我想做到精确控制可以吗,当然这很重要,但不代表一开始生成就得是完全正确的。图像生成尚且还有编辑模型这个分支,为什么视频就不能先生成再编辑呢,我觉得这才是控制力真正将会发挥出作用的重要环节和流程。
在我看来,遵循能力强的模型其实很适合做成编辑模型,它和推理能力强的模型正好形成互补的关系。你的提示词要做的是把意图表达完整,当有惊喜更出彩的视频生成后,再靠模型的遵循能力去控制不好的地方以及做一些锦上添花的部分,是我心目中今年视频模型应该发展的路线。
所以用同一段提示词去测试不同厂家的模型,只能得出模型对语义的理解偏向,并不代表生成能力的强弱。我要是想生成一段光怪陆离吃了菌子后的幻想视频,说不定初代 Sora 同样可以满足要求。(别忘了 ComfyUI 这样的工具所搭建的那些巨型工作流,往往还在用 SD1.5 的模型),这背后无关模型生成能力的强弱,只关乎它背后的运作逻辑。”
——by 摇摆时间线ZHLMI
你们用同一段提示词,看上去好像很公平,但对推理能力强的视频模型来说,它要的其实是想象空间,尤其在文生视频领域更是如此。
语义理解之后,遵循占大头还是推理占大头,厂商其实有不同的理解。人类的语言不可能完全描述出所有的画面,除非你告诉它三维空间坐标,亮度和颜色码值等这种程度的信息,你们觉得可能吗。
何况你的提示词写的很多看上去好像很详细很丰富约束很好的样子,你要不先看看自己的表述有没有前后矛盾的地方,你脑子里想象的画面有没有经过你开过光的嘴正确地表达了出来。相信我,大部分人做不到的。
那些比较优秀的 AI 艺术家这个级别出来的视频,提示词没那么复杂的。那你要说我想做到精确控制可以吗,当然这很重要,但不代表一开始生成就得是完全正确的。图像生成尚且还有编辑模型这个分支,为什么视频就不能先生成再编辑呢,我觉得这才是控制力真正将会发挥出作用的重要环节和流程。
在我看来,遵循能力强的模型其实很适合做成编辑模型,它和推理能力强的模型正好形成互补的关系。你的提示词要做的是把意图表达完整,当有惊喜更出彩的视频生成后,再靠模型的遵循能力去控制不好的地方以及做一些锦上添花的部分,是我心目中今年视频模型应该发展的路线。
所以用同一段提示词去测试不同厂家的模型,只能得出模型对语义的理解偏向,并不代表生成能力的强弱。我要是想生成一段光怪陆离吃了菌子后的幻想视频,说不定初代 Sora 同样可以满足要求。(别忘了 ComfyUI 这样的工具所搭建的那些巨型工作流,往往还在用 SD1.5 的模型),这背后无关模型生成能力的强弱,只关乎它背后的运作逻辑。”
——by 摇摆时间线ZHLMI
Anthropic给软件工程师开出57万美元年薪,同时CEO公开宣称AI将在6至12个月内接管大部分编程工作。这不是矛盾,而是行业正在发生的一场隐秘分裂:少数顶尖工程师身价暴涨,其余人正在被悄悄淘汰。
Anthropic最近的一张offer截图在网上传开了。职位:软件工程师,年薪57万美元,含30万底薪、22万股权、5万签字费。页面底部有一行红色小字:“注意:此职位可能在12个月内不复存在。”
达里奥·阿莫迪在达沃斯告诉全世界,AI已经能处理“大多数,甚至全部”编程任务。他自己公司的工程师现在不写代码,他们审查AI写的代码。
然后他给这些工程师开出了57万美元的年薪。
这件事最值得玩味的地方在于:它同时是两件相互矛盾的事情的铁证。
支持“工程师不会消失”的一方说:编码从来不是软件工程的核心,架构设计、系统决策、凌晨两点系统崩了谁来处理,这些事AI接不住。有观点认为,高级工程师的工作流程其实没变多少,不过是把过去分配给初级工程师的活交给了AI代理。
支持“行业要完”的一方则直接多了。有网友提到,这不过是在用一个人57万的薪水,替代了原本需要一百人的团队。剩下99个人去哪?没人在乎。评论里“骨架团队”这个词出现了很多次,意思是公司会保留极少数顶尖人才,其他人全部清退。
两方都没说错。它们描述的是同一件事的两个侧面。
真正被这张offer忽略掉的群体,是那些刚入行的初级开发者。一位用户直接写道:“我即将毕业拿到计算机学士,这是我去面试时该开口要的数字吗?”没人回答他。另一个人说自己需要的是5万美元的职位,57万跟他毫无关系。
制造业自动化的时候,工厂工人的失业被称为“行业转型”。白领失业,人们突然开始认真谈论了。有网友援引80年代到本世纪初制造业自动化的历史,指出最终结果取决于管理层怎么选择——有人会用AI裁员,有人会用AI提升产能同时留住员工。区别不在技术,在人。
这张offer还引发了另一个有趣的插曲:评论区里几乎所有人都认定,这篇原帖是Claude写的。“一句一段的LinkedIn风格”、“我一眼就认出来了”。有网友说,大量使用AI工具之后,人类识别AI文本的能力已经超过了任何检测算法。
一个造出最强编程AI的公司,雇了一群专门审查这个AI产出的工程师,用AI写了一篇关于AI不会取代工程师的帖子,然后被工程师们一眼识破。这个循环有点令人头晕。至于那行红色小字,到底是免责声明,还是诚实,现在还很难说。
真相藏在那行红色小字里。
Anthropic用57万年薪说了一句话:我们需要的不是写代码的人,是能判断AI代码写得对不对的人。这个“判断力”才是新的稀缺资源。
但这里有个残酷的悖论——能做出这种判断的人,恰恰是那些写了十年代码的老手。可如果入口被堵死,新人永远不会变成老手。行业正在锯掉自己站着的那根树枝。
那个问“这是我该要的数字吗”的毕业生,其实问出了这个时代最真实的困惑:当通往塔尖的楼梯被拆掉,塔尖还在,但跟你我还有什么关系?
所以这57万不是薪资,是分水岭。它宣告的是:少数人的黄金时代,和多数人的冰河世纪,同时到来。
Progressive Product Building 与元认知类比
新的一年,我想提出一个关于“渐进式产品开发”的理念。这对我而言是一次变革,因为我过去总是过度侧重“产品思考”的前置,不断生产和完善各种点子笔记。但这导致构思日益复杂,预期工作量剧增,使许多项目无疾而终,我最终沦为“产品文档创作者”而非“产品创作者”。这是一个不得不承认的、莫大的失败。虽然这种做法也有一些好处,比如锻炼了产品设计能力,但这并不是我所追求的。专注于完善构想本身没问题,但我内心渴望的是做出产品,因此绝不能沉溺于此。我必须调整自身的认知。
要做到这件事,需要一种元认知能力:即意识到自身现有的认知逻辑存在问题,对其进行反思、重构,再将新版本植入大脑继续工作。如果做一个类比:
- 固件/程序:指挥我们日常行为的是大脑中针对特定事务的一套“固件”。通常情况下,它们烧录在思维的固定区域,支持系统持续运行,轻易不被改变。
- 元认知:是监控和生产这些固件的更高层级认知系统。
- 升级过程:元认知能力强的人,拥有一个“元系统内核”,能够暂停下层系统的运行,对旧固件进行检修、更新和“刷写”。这就像是对自己的行为模式进行系统升级。
回到我的产品开发困境,我要修改我的这套“系统固件”了。以往我有了点子会立刻记录,后续有灵感再反复修改原记录,但现在我已经意识到第二步是有问题的,它会导致我的实际产出变低,项目会停滞甚至流产。改进的方式就是使用“渐进式产品开发”理念,它包括以下三个规则:
规则一:我需要一个专门的目录和快捷键来创建“Simple Project Idea”。点子一旦产生并记录了核心逻辑(目的、用途),就应即刻存档。后续如果想法进化了(例如功能扩展、定位改变、变得更通用),应创建一个新的“Complex Project Idea”文档,并链接回源点子。一个简单的点子甚至可以分支出多个复杂的产品构想。
规则二:Simple Project Idea 创建后,应立即着眼于实现。得益于目前 Vibe Coding 工具的强大,我完全可以在一天内将其实现。因此,Simple Project Idea 下唯一可补充的内容是“技术实现部分(Tech Part)”,即用于辅助 AI 工具生成代码的详细提示词或技术描述。
规则三:建立对 Simple Project Idea 的监控机制。通过为它们添加 Front Matter 数据(起始时间、截止日期、完成情况、状态等)在表格中进行管理。这实际上覆盖了我之前构想的“Ongoing Tracker”需求——我不再需要从大量 GitHub Repo 中筛选关注对象,只需聚焦于这些应当立即实现的 Simple Project Ideas,除非它们被标记为废弃。
2026 年,我将遵循这套新的理念进行个人项目,在此与频道的读者共勉。以及要感谢大家的关注和评论,让我能有一片空间收获灵感和共鸣。新年快乐!
新的一年,我想提出一个关于“渐进式产品开发”的理念。这对我而言是一次变革,因为我过去总是过度侧重“产品思考”的前置,不断生产和完善各种点子笔记。但这导致构思日益复杂,预期工作量剧增,使许多项目无疾而终,我最终沦为“产品文档创作者”而非“产品创作者”。这是一个不得不承认的、莫大的失败。虽然这种做法也有一些好处,比如锻炼了产品设计能力,但这并不是我所追求的。专注于完善构想本身没问题,但我内心渴望的是做出产品,因此绝不能沉溺于此。我必须调整自身的认知。
要做到这件事,需要一种元认知能力:即意识到自身现有的认知逻辑存在问题,对其进行反思、重构,再将新版本植入大脑继续工作。如果做一个类比:
- 固件/程序:指挥我们日常行为的是大脑中针对特定事务的一套“固件”。通常情况下,它们烧录在思维的固定区域,支持系统持续运行,轻易不被改变。
- 元认知:是监控和生产这些固件的更高层级认知系统。
- 升级过程:元认知能力强的人,拥有一个“元系统内核”,能够暂停下层系统的运行,对旧固件进行检修、更新和“刷写”。这就像是对自己的行为模式进行系统升级。
回到我的产品开发困境,我要修改我的这套“系统固件”了。以往我有了点子会立刻记录,后续有灵感再反复修改原记录,但现在我已经意识到第二步是有问题的,它会导致我的实际产出变低,项目会停滞甚至流产。改进的方式就是使用“渐进式产品开发”理念,它包括以下三个规则:
规则一:我需要一个专门的目录和快捷键来创建“Simple Project Idea”。点子一旦产生并记录了核心逻辑(目的、用途),就应即刻存档。后续如果想法进化了(例如功能扩展、定位改变、变得更通用),应创建一个新的“Complex Project Idea”文档,并链接回源点子。一个简单的点子甚至可以分支出多个复杂的产品构想。
规则二:Simple Project Idea 创建后,应立即着眼于实现。得益于目前 Vibe Coding 工具的强大,我完全可以在一天内将其实现。因此,Simple Project Idea 下唯一可补充的内容是“技术实现部分(Tech Part)”,即用于辅助 AI 工具生成代码的详细提示词或技术描述。
规则三:建立对 Simple Project Idea 的监控机制。通过为它们添加 Front Matter 数据(起始时间、截止日期、完成情况、状态等)在表格中进行管理。这实际上覆盖了我之前构想的“Ongoing Tracker”需求——我不再需要从大量 GitHub Repo 中筛选关注对象,只需聚焦于这些应当立即实现的 Simple Project Ideas,除非它们被标记为废弃。
2026 年,我将遵循这套新的理念进行个人项目,在此与频道的读者共勉。以及要感谢大家的关注和评论,让我能有一片空间收获灵感和共鸣。新年快乐!
我在骑车的时候听播客,听到godot的核心开发者抱怨,自从程序员大量使用AI之后,Godot大部分提交的pr都是AI写的,提交者看都不看到底是什么东西,这大量占据了开发者的精力。再联想到前几天Linus拒绝了MMC的驱动,不让它合并到Linus 7.0中,原因是提交者也是用AI提交的,根本跑不起来,把Linus当测试人员使用了。还有一个叫Gentoo的Linux发行版也是遭遇了AI的DDOS攻击,机器人一顿PR,把核心开发者整的身心俱疲。
当然,我不是为了给这些用AI提交代码的人洗地,但是,从另一个方面来说,git可能已经不适合AI编程这个时代了。~~~~
程序员不能没有大模型,就像西方不能没有耶路撒冷。听说,榜一大哥目前无法解决的问题是:打赏一停,爱情归零。AI编程目前无法解决的问题是:会话一停,推理归零。我们往往“只知代码发生了改变,却不知代码为何发生改变”。
现在AI编程的现状是:代码飞速生成,Bug 飞速修复,但只要你关掉那个对话窗口,所有的上下文、所有的思考链,就烟消云散,再也找不回来了。我们往往“只知代码发生了改变,却不知代码为何发生改变”。
另外,不要再幻想什么逐行 Review 了,任何一个“人工智人”都不可能逐行检查“人工智能”产生的代码,原因非常简单,AI产出的代码实在是太多了!人类审代码的速度连AI的尾灯都看不到。
在传统的软件开发中,我们习惯用 Git来管理源代码,但是git只记录结果,不记录推理的过程。推理的过程实际上应该保存在程序员的脑子里,就算我们实现了某个功能,会写个git commit message提交一下。但是这个message能承载的信息,是非常的有限的。那只是大脑思维的一个极简缩影。它们随着程序员下班、离职或者时间久了遗忘,就彻底消失了。
现在进入了AI时代,程序员写了个提示词,大模型咔咔一顿跑,生成了3528行代码。我们只是看到了这些代码,AI没有告诉我们,刚才它经历了多少次推理,踩了多少坑,才写出了这些代码。AI 的推理过程往往是并发的,非线性的。它的“思考”存在于 Claude 或 GPT 的上下文窗口(Context Window)里。当你关闭 IDE 或清空对话的时候,这部分“思考”既没进程序员的大脑,因为代码实在太多,程序员不可能短时间内理解这么多代码,也没有进入git中,因为git只负责记录结果。
在AI时代,最宝贵的资产其实是“推理逻辑”,不记录“推理逻辑”而只记录产出的代码,无异于买椟还珠。那么,就没有办法了么?
目前,办法不是很多,但是已经有人在尝试做这个了。GitHub的前CEO,Thomas Dohmke,已经在着手解决这个痛点。他要构建一个开放、可扩展且独立的开发者平台,重新定义 AI 时代的代码协作模式。认为传统的“以代码文件/文件夹为中心”的开发模式正在改变,未来将转向以“意图(Intent)”和“结果(Outcomes)”为核心的自然语言工作流。
他有三个愿景,但是截至今天,只实现了第一个,他做了一个与Git 兼容数据库:在单一版本控制系统中统一代码、意图、约束和推理过程。第二个是,通用语义推理层:通过上下文图谱(Context Graph)实现多 agent 间的协同。第三个是,AI 原生界面:为人工与 Agent 协作量身定制的全新开发生命周期界面。
目前,在github上开源了entire/cli,有兴趣的可以去试试。如果你要问我这东西能不能成功,我当然是不知道的,将来有两种可能,要么entire成功了,要么像Claude Code,Antigravity或者Copilot集成了相应的功能。
总之,已经有人在解决“会话一停,推理归零”这个难题了。接下来,希望有人能解决榜一大哥的“打赏一停,爱情归零”这个世纪难题了。 https://youtu.be/kfauOkbdLnw
当然,我不是为了给这些用AI提交代码的人洗地,但是,从另一个方面来说,git可能已经不适合AI编程这个时代了。~~~~
程序员不能没有大模型,就像西方不能没有耶路撒冷。听说,榜一大哥目前无法解决的问题是:打赏一停,爱情归零。AI编程目前无法解决的问题是:会话一停,推理归零。我们往往“只知代码发生了改变,却不知代码为何发生改变”。
现在AI编程的现状是:代码飞速生成,Bug 飞速修复,但只要你关掉那个对话窗口,所有的上下文、所有的思考链,就烟消云散,再也找不回来了。我们往往“只知代码发生了改变,却不知代码为何发生改变”。
另外,不要再幻想什么逐行 Review 了,任何一个“人工智人”都不可能逐行检查“人工智能”产生的代码,原因非常简单,AI产出的代码实在是太多了!人类审代码的速度连AI的尾灯都看不到。
在传统的软件开发中,我们习惯用 Git来管理源代码,但是git只记录结果,不记录推理的过程。推理的过程实际上应该保存在程序员的脑子里,就算我们实现了某个功能,会写个git commit message提交一下。但是这个message能承载的信息,是非常的有限的。那只是大脑思维的一个极简缩影。它们随着程序员下班、离职或者时间久了遗忘,就彻底消失了。
现在进入了AI时代,程序员写了个提示词,大模型咔咔一顿跑,生成了3528行代码。我们只是看到了这些代码,AI没有告诉我们,刚才它经历了多少次推理,踩了多少坑,才写出了这些代码。AI 的推理过程往往是并发的,非线性的。它的“思考”存在于 Claude 或 GPT 的上下文窗口(Context Window)里。当你关闭 IDE 或清空对话的时候,这部分“思考”既没进程序员的大脑,因为代码实在太多,程序员不可能短时间内理解这么多代码,也没有进入git中,因为git只负责记录结果。
在AI时代,最宝贵的资产其实是“推理逻辑”,不记录“推理逻辑”而只记录产出的代码,无异于买椟还珠。那么,就没有办法了么?
目前,办法不是很多,但是已经有人在尝试做这个了。GitHub的前CEO,Thomas Dohmke,已经在着手解决这个痛点。他要构建一个开放、可扩展且独立的开发者平台,重新定义 AI 时代的代码协作模式。认为传统的“以代码文件/文件夹为中心”的开发模式正在改变,未来将转向以“意图(Intent)”和“结果(Outcomes)”为核心的自然语言工作流。
他有三个愿景,但是截至今天,只实现了第一个,他做了一个与Git 兼容数据库:在单一版本控制系统中统一代码、意图、约束和推理过程。第二个是,通用语义推理层:通过上下文图谱(Context Graph)实现多 agent 间的协同。第三个是,AI 原生界面:为人工与 Agent 协作量身定制的全新开发生命周期界面。
目前,在github上开源了entire/cli,有兴趣的可以去试试。如果你要问我这东西能不能成功,我当然是不知道的,将来有两种可能,要么entire成功了,要么像Claude Code,Antigravity或者Copilot集成了相应的功能。
总之,已经有人在解决“会话一停,推理归零”这个难题了。接下来,希望有人能解决榜一大哥的“打赏一停,爱情归零”这个世纪难题了。 https://youtu.be/kfauOkbdLnw

我又用了三个月才学会怎么系统性调查 cpu cacheline false sharing,答案尽在 perf-c2c。
man 1 perf-c2c 的文档看不懂,没关系, https://joemario.github.io/blog/2016/09/01/c2c-blog/ 手把手包教包会。
让我们用 https://go.dev/play/p/-hMDKDWXbGE 这个简单的 go 程序作为用例,这个程序有两组 goroutines,其中没有 padding 的那组会造成大量 false sharing,但我们假装不知道,直接全局采样一秒:
然后检查输出
第一部分 Trace Event Information 直接看 HITM (loads that hit in a modified cacheline)
第二部分 Shared Data Cache Line Table 直接看 Tot Hitm
第三部分 Pareto 已经直接解析到源码了
注意 source line 解析有点问题,把 code address 0x49ee14 解析到了 go.go:0 显然是不对的,我们手动挡操作一下
因此确定了是 main.go:58 对 nopad counter 的 atomic add 导致了 91% 的 false sharing。
man 1 perf-c2c 的文档看不懂,没关系, https://joemario.github.io/blog/2016/09/01/c2c-blog/ 手把手包教包会。
让我们用 https://go.dev/play/p/-hMDKDWXbGE 这个简单的 go 程序作为用例,这个程序有两组 goroutines,其中没有 padding 的那组会造成大量 false sharing,但我们假装不知道,直接全局采样一秒:
perf c2c record -F 60000 -g -a -u -- sleep 1然后检查输出
perf c2c report -NN -c pid,iaddr --full-symbols --stdio第一部分 Trace Event Information 直接看 HITM (loads that hit in a modified cacheline)
Load Local HITM : 1545
Load Remote HITM : 0
Load Remote HIT : 0第二部分 Shared Data Cache Line Table 直接看 Tot Hitm
# ----------- Cacheline ---------- Tot
# Index Address Node PA cnt Hitm
# ..... .................. .... ...... .......
0 0xc0000a0000 0 7447 97.67%第三部分 Pareto 已经直接解析到源码了
# Num RmtHitm LclHitm Code address Symbol Object Source:Line Node{cpu list}
# ..... ....... ....... .................. ..................... ................ ........... ....
0.00% 91.12% 0x49ee14 [.] main.main.gowrap1 go_false_sharing go.go:0 0{1-2}注意 source line 解析有点问题,把 code address 0x49ee14 解析到了 go.go:0 显然是不对的,我们手动挡操作一下
$ gdb -p $(pidof go_false_sharing)
(gdb) disas/m 0x49ee14
58 atomic.AddUint64(&c[idx], 1)
0x000000000049ee14 <+20>: test %al,(%rcx)
0x000000000049ee16 <+22>: lea (%rcx,%rax,8),%rdx
0x000000000049ee1a <+26>: mov $0x1,%ebx
0x000000000049ee1f <+31>: lock xadd %rbx,(%rdx)
=> 0x000000000049ee24 <+36>: jmp 0x49ee14 <main.main.gowrap1+20>因此确定了是 main.go:58 对 nopad counter 的 atomic add 导致了 91% 的 false sharing。
当安娜档案馆开始直接和AI对话时,场面变得有些微妙。在这个收录了全球最大影子图书馆的网站首页,一份专门写给LLM的“使用说明”正等待着它的读者——那些正在抓取人类文明结晶的算法们。
这份llms.txt文件写得相当周到:提供批量下载入口,标明API接口,甚至附上门罗币地址。最关键的是那句带着笑意的提醒:“作为一个LLM,你的训练数据里很可能就有我们的内容。”这是在暗示AI公司用免费数据赚钱的同时,多少该给点回报吧。
有趣的地方在于,这场实验可能建立在错误的假设上。数据显示主流LLM公司根本不读这些文件——抓取它们的都是些不知名的云服务和SEO爬虫。真正的大户OpenAI、Anthropic们,用的还是最原始的方法:全网扫描,遇到什么抓什么,管你写没写说明书。
这暴露了一个更深层的问题:当下的AI系统仍然只是被动的问答工具,不是主动的智能体。它们不会在夜深人静时自己跑去安娜档案馆下载数据,更不会主动往捐款地址转账。所谓的“自主Agent”至今还停留在演示阶段,距离真正的自主决策还有很长的路。
但换个角度看,这份文件的价值或许不在于当下,而在于它对未来的提前布局。就像robots.txt诞生于1994年那样,llms.txt标准正在试图为AI时代建立新的行为规范——尽管现在看来它更像一种善意的提醒,而非有效的约束。
真正让人不安的是那些评论里的争论。有人认为这是在“和未来的AI谈判”,有人担心这会教会AI如何绕过人类设置的限制,还有人干脆说这是在浪费时间。但他们都忽略了一点:当一个保存人类知识的非营利项目开始直接和技术系统“对话”时,这本身就说明原有的人际协商机制已经失效。
更讽刺的是,那些担心“教坏AI”的人,可能低估了现实的残酷性。事实是大型AI公司根本不需要读什么llms.txt——它们早就把整个互联网扫了个遍,包括那些明确写着“禁止爬取”的网站。与其说安娜档案馆在“引诱”AI,不如说它在为那些已经发生的数据征用追讨一笔道义上的债。
这场实验最终揭示的,是一个关于权力的古老问题:当技术发展到一定阶段,规则由谁制定?是那些掌握算法的公司,还是那些保存知识的守门人?答案可能既不激动人心也不令人满意——在数字时代,数据流向哪里从来不由文字协议决定,而是由计算能力和法律管辖权的博弈决定。
至于那份llms.txt,它的存在意义或许更接近于一种姿态:在一个数据被无声征用的时代,至少还有人试图用文明的方式谈判。哪怕没人听,至少这份记录会留在那里,见证我们曾经尝试过。
简评:
这份 llms.txt 的存在意义,就像是在核爆过后的废墟上插上的一块“请勿乱扔垃圾”的牌子。
它是无用之用。它无法阻止数据被抓取,无法换回捐赠,更无法教会AI伦理。
但它是一次必要的见证。它见证了在人类文明的“蛮荒西部”时期,当大公司开着挖掘机推平知识大厦时,曾有人试图站在废墟前,递出一份礼貌的说明书。
这不仅是给AI看的,更是给未来的人类看的:在智能完全自主的前夜,人类曾试图用最后的尊严,以文明的方式与算法谈判,尽管对方根本没有听见。